scikit-learn - 用於構建分類器的最基本的機器學習算法
這是 Python 中最廣為人知的機器學習模組,主要用於構建分類器。這是 Python 中最廣為人知的機器學習模組,我建議對機器學習感興趣的人,前往官方網站查看它們提供的各種模型。它還提供了大量的範例供你參考。
今天,我想花點時間使用多項式回歸(Polynomial Regression)來測試比特幣價格的預測。
什麼是多項式回歸 (Polynomial Regression)?
多項式回歸是迴歸分析的一種形式,它模型化了自變數 x 與因變數 y 之間的關係,作為 x 的 n 次多項式。簡而言之,它是多元線性回歸的一個特殊情況(以 x 和 x² 作為兩個解釋變數)。
在python里,首先要先設定以下。
#save instance of polynomial features
poly = PolynomialFeatures(degree=2, include_bias=False)
degree=2 表示我們想要使用二次多項式include_bias=False 應該設置為 False,因為我們稍後將與 LinearRegression() 一起使用 PolynomialFeatures。x_2 = df_all[['Bitcoin']].values # Popularity Index
poly_features_2= poly.fit_transform(x_2.reshape(-1,1))
poly_reg_model.fit(poly_features_2, y)
Fitting (擬合)意味著透過讓模型知道特徵(poly_features)和響應(y)值來訓練它。當進行擬合/訓練我們的模型時,我們基本上指示它解出多項式函數中的係數(用粗體標記)。
y = ß0 + ß1x + ß2x2
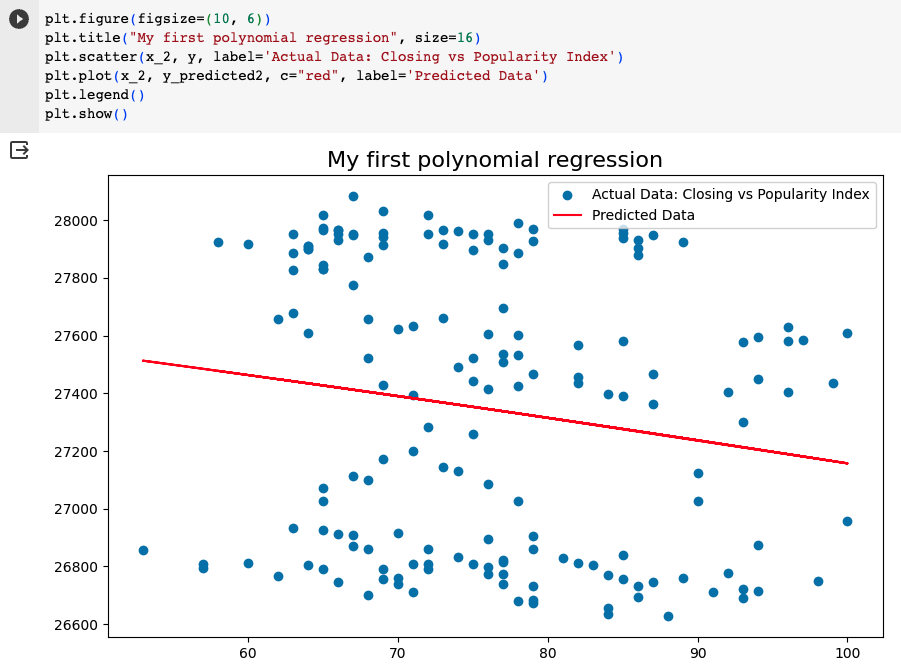
上圖可以顯示預測幾乎停留在價錢範圍的中間點。
我們繼續套用一下train_test_split去訓練一下polynomial model。
X_train、X_test、y_train、y_test:train_test_split 將我們的特徵 (poly_features) 和回應 (y) 分為訓練和測試組。
可以看在 train_test_split 方法中,我們定義了所有的特徵: (poly_features) 和所有的回應 (y)。然後,通過 test_size,我們設置了多少百分比的特徵 (poly_features) 和回應 (y) 用於測試我們模型的預測能力(30% (0.3))。
random_state 需要接受一個整數值:這樣每次重新運行 train_test_split 時,你將獲得相同的結果。
最後我們用RMSE(root mean square error 均方根誤差)來看看我的模型離實際數據有多準確。RMSE越低,就越準確。
可以看到用比特幣的x_1(Volume), x_2(Volume)來預測y(Close Price)並沒有很準確。
用圖表顯示這模型的預測: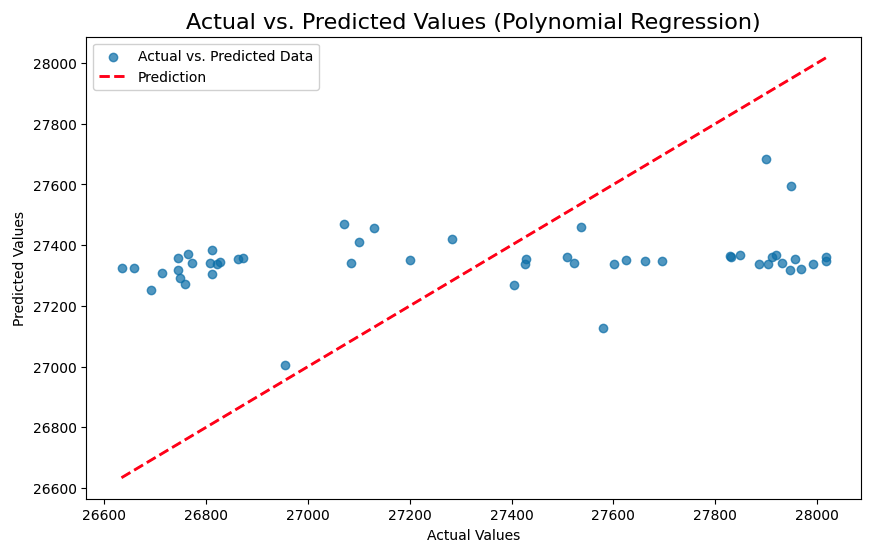
說實在的,我還蠻訝異比特幣的交易量跟他的價格起伏沒有相連性。因為沒關聯性,導致以上模型的預測是最不準確的。
以上方法大部分是參考且引用這文章裏的setup,有興趣的朋友可以自已看看喔。
Ref:
https://scikit-learn.org/stable/
https://data36.com/polynomial-regression-python-scikit-learn/
對 dbt 或 data 有興趣?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加
Ref:
https://levelup.gitconnected.com/20-pandas-functions-for-80-of-your-data-science-tasks-b610c8bfe63c

